Knowledge Enhanced Contextual Word Representations 논문 세미나
거대한 NLP research Lib를 구축하는 allennlp에서 2019년에 낸 논문이다.
Introduction (하고자 하는것, 효과, 요약)
아무 large-Scale 모델에 기존 KB 정보를 추가하는 일반적인 방법을 제안하였으며,
이를 통해 1) 자주 등장하지 않는 상식적인 지식과 2) 길이가 길어 long-dependency 문제가 있는 지식과 같이 attention에서 선택되지않아 학습하기 어려운 지식을 encoding에 포함할 수 있다.
여러 토큰/복합명사로 개체명이 구성될 수 있기 때문에 통합해서 관련 정보를 넣는 과정이 필요하여 진행하는 모델이다. ERINE, KnowBERT 등이 있다.
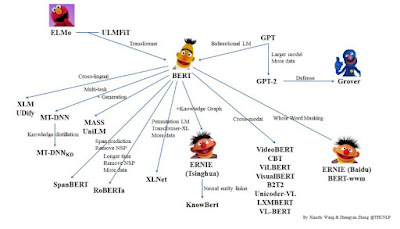
이에 대한 구현방법은
0) 모델 중간 레이어의 값을 뽑아서
1) KB 개체명 활용 rule로 entity span을 뽑고
2) KB 활용 rule 방식인 entity linker로 관련있는 entity-span embedding을 뽑은 뒤
3) entity-span embedding과 입력 word간의 attention을 구해서
4) 다시 레이어에 집어넣었다.
즉, 기존 레이어 사이의 KAR라는 신규 레이어를 집어넣어 부가적인 entity 정보를 추가하였다. 이렇게 KB를 BERT와 결합한 전 과정이 제안사항이며 KAR로 명명한다. 배포한 pre-trained model은 KnowBERT로 명명한다.
(KAR : Knowledge Attention and Re-contextualization)
제안모델을 기존 BERT모델에 붙여 Pretrain할 때 Masked LM perplexity와 Wiki 데이터에서 entity를 masking한 것에 대한 복구 성능 향상을 보임으로써, entity-지식에 대한 상식이 늘어난 것을 증명하였다. 뿐만아니라 관계 추출, entity typing과 같이 지식추출과 연관된 공개 downstream task에서도 좋은 성능을 보임을 증명하였다.
Background (배경지식)

용어설명
개체명 연결(Named Entity Linking)은 주어진 문장에 출현한 단어를 위키피디아와 같은 지식 기반 (Knowledge base) 상의 하나의 개체와 연결하여 특정 개체가 무엇인지 식별하는 작업이다. 예를 들어 “파리는 프랑스의 수도이다.”라는 문장이 주어졌을 때, 문장에서 언급된 단어인 “파리”가 “파리(도시)”를 의미하는지 파리(곤충)”을 의미하는지 연결하는 작업을 말한다
개체의
표현이 포함된 문장을 Context, 개체의 표현을 Mention이라 한다.
•coreference resolution(상호 참조 해결): 임의의 개체(entity)에 대해 다른 표현으로 사용되는 단어들을 찾아 서로 같은 개체로 연결해주는 자연어처리 문제
•coreference(상호참조): 같은 개체를 가리키는 mention들(갓 볶은 원두로 만든 커피, 카페인, 그것)
•mention: 대상이 되는 모든 명사구(갓 볶은 원두로, 갓 볶은 원두로 만든 커피)
•head(중심어): mention에서 해당 구의 실질적인 의미를 나타내는 단어(갓 볶은 원두로 만든 커피)
Proposed Method
1] Knowledge Base
본 논문에서는 아래 세개로 KB를 가정하여 사용하였으며, 이는 KAR 적용 순서 [1]~[2]에서 후보군 추출에 사용한다.
1) 다양한 종류의 KB 중 가장 보편적인 형태의 고정된 KB 구성을 사용하였으며, 이는 아래와 같다.
(1) typical graph structure
[subj, rel, obj] - triple 형태의 지식으로 나타낸 어휘목록 사이의 의미관계
(2) entity metadata without graph
synset(유의어집단) & definition (간략하고 일반적인 정의)
2) KB에 entity candidate selector가 있는데, 이는 텍스트를 입력하면 C(잠재적 엔터티 목록) 반환하는 것이다.

주어진 candidate 외에 word+NULL을 넣어 false positive를 방지할 수 있다. 이 논문은 entity linking score가 모두 threshold 이하인 경우, NULL embedding으로 하였다.
3) candidate entity의 개수제한을 둔다..
여기서는 30개로 하였다.
candidate select는 개수 제한이 있는 rule기반 방식으로, 굉장히 빠른 장점이 있지만, KB 크기만큼 메모리를 먹는 단점이 있다.
2] KAR 구조

Mention-span representation 생성

Entity Linker
*이 때, 모든 사항이 threshold를 넘지 않으면 null로 구성되게 하는 점이 흥미롭다. 초기값이 잘못나오면 다 낮게나올수도 있는데, 이러면 학습이 안되지않나?



Knowledge enhanced entity-span representation
Alignment of BERT and entity vectors
W2 = W1 : tied autoencoder처럼 projection weight를 그대로 뒤집어서 본래차원으로 돌려서 초기화한다.
3] 학습순서, 방법
학습 순서가 좀 특이한데, 1) Pretrained Bert를 사용하여 2) entity embedding과 entity span vector를 여기서 나온 loss를 사용해 먼저 학습하고 3) 복구하는애를 축소한애랑 같은 weight를 사용하게 하여 파라미터 unfreeze를 하고 전체적으로 모든 파라미터를 학습시킨다.
아마 그냥 학습시키게 되면 학습이 잘 안되나보다...

Experiments
1) 실험 데이터, 실험방식, 성과
12GB GPU RAM이 있는 titan x로 학습시켰다고 한다. 비용이 싸네
제안모델을 기존 BERT모델에 붙여 Pretrain할 때 Masked LM perplexity와 Wiki 데이터에서 entity를 masking한 것에 대한 복구 성능 향상을 보임으로써, entity-지식에 대한 상식이 늘어난 것을 증명하였다. 뿐만아니라 관계 추출, entity typing과 같이 지식추출과 연관된 공개 downstream task에서도 좋은 성능을 보임을 증명하였다.
Conclusion
기여도, 활용방안, 추후연구방향
수미상관임
* 금융 기반 단어로 모델을 pretrain 하는 대신에, 기학습된 large-model에 도메인(금융) entity 정보를 적은 리소스로 추가하여 사용할 수 있지 않을까?
* 그것을 위해서는 금융 KB 구축이 우선이고, 그 KB는 synset, 정의, 의미관계정도로 구성?
----------------------------------------------------------------------------------------------------
논문 출처
https://arxiv.org/pdf/1909.04164.pdf
Github
https://github.com/allenai/kb
참고자료
https://paperswithcode.com/task/entity-typing
https://www.koreascience.or.kr/article/CFKO201832073078621.pdf
댓글
댓글 쓰기