ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators 논문세미나
electra 리뷰
Introduction
장점 : 경량화
*성능도 4배 많은 파라미터를 가진 모델과 비교하여 glue기준 상위권 유지, SQuAD는 state of the art
1) distilbert, mobilebert와 달리 inference뿐만 아니라 pretrain 단계에서의 계산 축소도 고려하여, 1/4수준으로 경량화하였으며,
2) 학습시 mask 된 15%가 아닌 모든 token을 학습에 활용하여 학습 효율성이 올라감
3) 실 사용하는 모델의 입력으로 MASK를 사용하지 않아, 더 의미있는 학습 (실제로 사용시 학습이 많이되는 [MASK] 토큰을 사용하지 않기 때문)
Related works
1. Self-Supervised Pretraining for NLP
BERT, MASS, UniLM, ERINE, SpanBERT, XLNET
경량화모델인 TinyBERT, MobileBERT 등 등등..
Electra의 경우 SpanBERT의 영향을 많이 받았으며, replaces span dectection으로 해도 재밌을듯.
2. GAN
현재 text에 적용된 GAN 방식은 일반 MLE학습에 비해 뒤쳐짐. 본 모델이 text에 활용되는 GAN과 다른점은
1) Generator와 Discriminator의 loss를 adversarial하게 학습하지 않고, MLE로 학습함
2) 생성을 위한 랜덤 노이즈벡터가 아닌, generator가 빈칸을 채우는 방식으로 학습함 (MaskGAN에 가까움)
3) Generator가 원래 토큰과 동일한 토큰을 생성했을 때, GAN은 negetive sample (fake)로 간주하지만 ELECTRA는 positive sample로 간주함
3. Contrastive leaning
Electra의 경우 NCE (Logistic regression시에 한개의 positive sample과 나머지 noise sample을 놓고 학습시키는 방식)과 연관이 있다.
개념적으로 보면, Electra는 Word2Vec의 CBOW with Negative Sampling 버전과 같다. 여기서는 본래 학습데이터 분포에서 가져왔느냐, 아니면 치환된거냐 비교하는 방식으로말이다. word2vec은 generator모델에 비해 unigram token frequencies에서 가져온 간단한 조건부 확률에서 가져온다는 차이가 있다.
(Negative Sampling : 예측 후보 class가 많은 softmax 문제를 logit으로 치환, 샘플링된 일부만 0으로 학습, 답은 1로 학습하는 방식)
Methods



Experiments
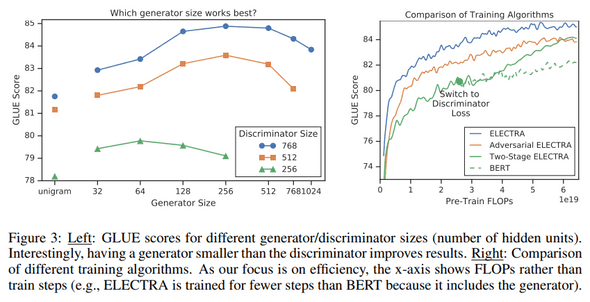

4. 효과분석 - ablation study *pingpong 복붙
ELECTRA 15% : ELECTRA의 구조를 유지하되, discriminator loss를 입력 토큰의 15%만으로 만들도록 세팅
Replace MLM : Discriminator를 MLM 학습을 하되, [MASK]로 치환하는 게 아니고 generator가 만든 토큰으로 치환
All-Tokens MLM : Replace MLM처럼 하되, 일부(15%) 토큰만 치환하는 게 아니고 모든 토큰을 generator가 생성한 토큰으로 치환
ELECTRA 15%는 토큰에 대한 학습 효율(15% vs 100%) 때문에 성능 차이가 생겼다는 것을 보이기 위한 목적,
Replace MLM는 pre-training 때만 사용하고 fine-tuning 때는 없는 [MASK] 토큰 때문에 생긴 성능 차이를 보이기 위한 목적으로 보입니다.
All-Tokens MLM은 이 세팅의 성능을 좀 더 개선하기 위해 sigmoid 레이어를 통해 입력 토큰을 복사할지 결정하는 확률 을 뽑는 매커니즘을 도입
appendix
We briefly describe a few ideas that did not look promising in our initial experiments:
• We initially attempted to make BERT more efficient by strategically masking-out tokens
(e.g., masking our rarer tokens more frequently, or training a model to guess which tokens
BERT would struggle to predict if they were masked out). This resulted in fairly minor
speedups over regular BERT.
• Given that ELECTRA seemed to benefit (up to a certain point) from having a weaker generator (see Section 3.2), we explored raising the temperature of the generator’s output softmax
or disallowing the generator from sampling the correct token. Neither of these improved
results.
• We tried adding a sentence-level contrastive objective. For this task, we kept 20% of input
sentences unchanged rather than noising them with the generator. We then added a prediction head to the model that predicted if the entire input was corrupted or not. Surprisingly,
this slightly decreased scores on downstream tasks.
기타
electra https://arxiv.org/abs/2003.10555
contrastive-learning 방식 공부, class간의 연관성이 높은 경우를 해소할수있을거같음
https://lilianweng.github.io/lil-log/2021/05/31/contrastive-representation-learning.html
Negative Sampling https://towardsdatascience.com/nlp-101-negative-sampling-and-glove-936c88f3bc68
댓글
댓글 쓰기